ansibleBook https://bjpcjp.github.io/2022/07/07/ansible.html
TOC
adhoc commands
best practices
certificates
cookbooks
deployment
docker
getting started
inventories
kubernetes
local devt
on Windows
playbook pt2
playbooks
playbooks-org
server security
tower CI/CD
Control node
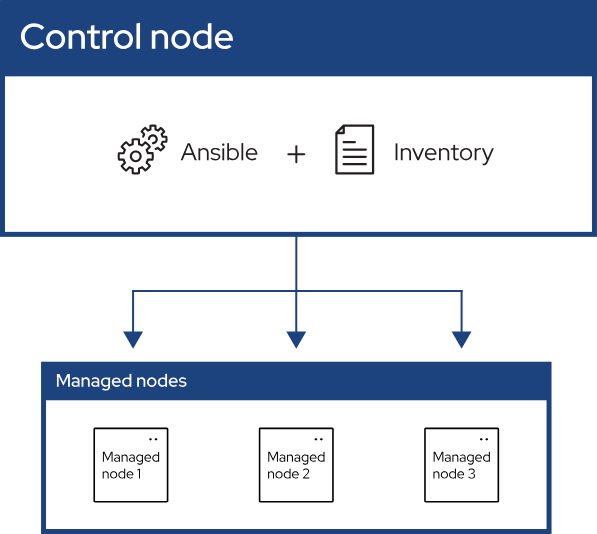
A system on which Ansible is installed. You run Ansible commands such as ansible or ansible-inventory on a control node.
Inventory
A list of managed nodes that are logically organized. You create an inventory on the control node to describe host deployments to Ansible.
Managed node
A remote system, or host, that Ansible controls.
[myhosts]
192.0.2.50
192.0.2.51
192.0.2.52ansible myhosts -m ping -i inventory.ini
myhosts:
hosts:
my_host_01:
ansible_host: 192.0.2.50
my_host_02:
ansible_host: 192.0.2.51
my_host_03:
ansible_host: 192.0.2.52leafs:
hosts:
leaf01:
ansible_host: 192.0.2.100
leaf02:
ansible_host: 192.0.2.110
spines:
hosts:
spine01:
ansible_host: 192.0.2.120
spine02:
ansible_host: 192.0.2.130
network:
children:
leafs:
spines:
webservers:
hosts:
webserver01:
ansible_host: 192.0.2.140
webserver02:
ansible_host: 192.0.2.150
datacenter:
children:
network:
webservers:Creating a playbook
Playbook
A list of plays that define the order in which Ansible performs operations, from top to bottom, to achieve an overall goal.
Play
An ordered list of tasks that maps to managed nodes in an inventory.
Task
A list of one or more modules that defines the operations that Ansible performs.
Module
A unit of code or binary that Ansible runs on managed nodes. Ansible modules are grouped in collections with a Fully Qualified Collection Name (FQCN) for each module.
- Create a file named
playbook.yamlin youransible_quickstartdirectory, that you created earlier, with the following content:
- name: My first play
hosts: myhosts
tasks:
- name: Ping my hosts
ansible.builtin.ping:
- name: Print message
ansible.builtin.debug:
msg: Hello world
-
Run your playbook.
ansible-playbook -i inventory.ini playbook.yaml
ansible #inventory
Inventory in Ansible is a crucial concept, essential for defining and managing the servers, machines, or devices on which Ansible will run tasks. Here’s a breakdown of what inventory means in the context of Ansible:
Definition
- Inventory: An inventory is a collection of hosts (servers, devices, etc.) against which Ansible can execute tasks. It’s essentially a list of nodes or machines that Ansible can manage.
Format
- Hosts and Groups: The inventory can list individual hosts or group them. Groups can have child groups, allowing for complex groupings and hierarchies.
- File Formats: The inventory file can be in various formats, including INI-like simple text files or YAML files. Ansible also supports dynamic inventories, where the inventory is generated by an external system or script.
Basic Example
- INI Format:
[webserver] server1.example.com server2.example.com [database] dbserver.example.com - YAML Format:
all: children: webserver: hosts: server1.example.com: server2.example.com: database: hosts: dbserver.example.com:
Key Features
- Variables: Inventory can also define variables for hosts or groups. These variables can be used to customize Ansible’s behavior for different hosts.
- Connection Details: It can include details like the IP address, domain, or other connection information (SSH port, user, etc.).
- Dynamic Inventory: For environments that change frequently (like cloud environments), Ansible can use dynamic inventories that are not static files but scripts or programs returning the inventory.
Usage
- Specifying Inventory: When running Ansible commands or playbooks, you specify which inventory to use. This can be a path to a file or a script for dynamic inventory.
- ansible.cfg: The default inventory file location can be set in Ansible’s configuration file,
ansible.cfg.
Importance
- Orchestration: Inventory is crucial for orchestrating tasks across multiple servers or environments. It tells Ansible “what” it will be managing or automating.
- Scalability: Inventories make managing large numbers of servers feasible, as they can be organized into manageable groups.
Best Practices
- Keep It Simple: Start with a simple inventory and expand as needed.
- Version Control: Keep your inventory files under version control.
- Security: Be mindful of sensitive data in inventory files. Use Ansible Vault for encryption if needed.
In summary, the inventory in Ansible is a foundational element for defining which systems your Ansible playbooks and roles will interact with. It’s flexible enough to handle a small number of servers or scale up to a large, dynamic infrastructure.
Ansible roles are a powerful feature for organizing and reusing code in Ansible. They help in managing complex playbooks by breaking them down into smaller, reusable components. Here’s an overview of what roles are and how they work in Ansible:
Definition and Purpose
- Roles: A role is a set of related tasks, variables, files, and handlers that are organized in a predefined directory structure. Roles allow you to group content, making it easier to reuse and redistribute.
- Modularity and Reusability: Roles promote modularity and reusability. By using roles, you can easily share and use code for common tasks across different playbooks.
Directory Structure
A typical role directory structure looks like this:
role_name/
├── defaults/ # Default variables for the role
│ └── main.yml
├── files/ # Files to be transferred to the target system
├── handlers/ # Handlers, which can be used by this role or even anywhere outside this role
│ └── main.yml
├── meta/ # Metadata for the role, including dependencies
│ └── main.yml
├── tasks/ # Main list of tasks that the role executes
│ └── main.yml
├── templates/ # Templates files, usually using Jinja2 syntax
├── tests/ # Test code for the role
└── vars/ # Other variables for the role
└── main.yml
Key Components
- Tasks: The
tasksdirectory contains the main list of tasks that the role will execute. - Handlers: In the
handlersdirectory, you define handlers, which are tasks that only run when notified. - Defaults: The
defaultsdirectory stores default variables for the role. - Vars: The
varsdirectory contains other variables for the role, usually with higher priority than defaults. - Files and Templates:
filesandtemplatesdirectories contain files and templates that can be deployed to target systems. - Meta: The
metadirectory contains metadata, like role dependencies.
Creating a Role
- Use the
ansible-galaxycommand to create a new role with the basic directory structure:ansible-galaxy init role_name
Using Roles in Playbooks
- Roles are called within playbooks. Here’s a basic example of how a role is referenced in a playbook:
- hosts: webservers roles: - role: nginx - role: php php_versions: ['7.4', '8.0']
Variables and Overriding
- Variables in roles can be overridden by passing them in playbooks or setting them in different variable files.
Role Dependencies
- Roles can depend on other roles, and these dependencies are defined in the
meta/main.ymlfile of the role. Ansible will automatically include and execute dependent roles.
Best Practices
- Modular Design: Design roles to be as modular and reusable as possible.
- Documentation: Document each role, including its purpose, variables, and dependencies.
- Version Control: Keep roles in version control systems for better management.
- Testing: Regularly test roles independently to ensure they function as expected in different environments.
Sharing and Reuse
- Ansible Galaxy: You can share and reuse roles via Ansible Galaxy, a hub for finding, reusing, and sharing Ansible content.
Roles are essential for scaling and managing larger, more complex Ansible configurations, allowing for cleaner code, easier maintenance, and better organization.
Docs
Difference Between task and play
In Ansible, “play” and “task” are fundamental concepts that are part of its automation and orchestration framework. Understanding the difference between these two is crucial for effectively using Ansible.
-
Play:
- A “play” is a collection of tasks. It’s essentially a set of instructions that you want to execute on a particular set of hosts or groups defined in your inventory.
- Each play is defined within a playbook. A playbook can contain one or more plays.
- A play allows you to define the target machines (hosts), variables, tasks, and handlers that should be applied to those hosts.
- It’s the top-level component in an Ansible playbook, making it possible to orchestrate multi-machine deployments, where different sets of tasks might be applied to different sets of machines.
-
Task:
- A “task” is a single action that you want to perform. It’s the smallest unit of work in Ansible.
- Tasks are executed sequentially, one after the other, within a play.
- A task generally represents calling an Ansible module, like installing a package, copying a file, executing a script, etc.
- Each task should ideally represent a single idempotent action that makes a small change to the system or checks a specific piece of system state.
To illustrate, consider an Ansible playbook (which is a YAML file):
- name: Play 1 - Configure Web Servers
hosts: webservers
tasks:
- name: Install Apache
ansible.builtin.yum:
name: httpd
state: present
- name: Start Apache
ansible.builtin.service:
name: httpd
state: started
- name: Play 2 - Configure Database Servers
hosts: databases
tasks:
- name: Install MySQL
ansible.builtin.yum:
name: mysql-server
state: present
- name: Start MySQL
ansible.builtin.service:
name: mysqld
state: startedIn this playbook:
- There are two plays, each targeting different sets of hosts (
webserversanddatabases). - Each play contains multiple tasks, such as installing and starting services.
The playbook orchestrates the entire workflow across different sets of servers, with each play and its tasks focused on a specific aspect of the overall configuration.
ungrouped: hosts: mail.example.com: webservers: hosts: foo.example.com: bar.example.com: dbservers: hosts: one.example.com: two.example.com: three.example.com:
Even if you do not define any groups in your inventory file, Ansible creates two default groups: all and ungrouped. The all group contains every host. The ungrouped group contains all hosts that don’t have another group aside from all. Every host will always belong to at least 2 groups (all and ungrouped or all and some other group). For example, in the basic inventory above, the host mail.example.com belongs to the all group and the ungrouped group; the host two.example.com belongs to the all group and the dbservers group. Though all and ungrouped are always present, they can be implicit and not appear in group listings like group_names.
How to name groups in ansible
-
What - An application, stack or microservice (for example, database servers, web servers, and so on).
-
Where - A datacenter or region, to talk to local DNS, storage, and so on (for example, east, west).
-
When - The development stage, to avoid testing on production resources (for example, prod, test).
parentchildansible https://docs.ansible.com/ansible/latest/inventory_guide/intro_inventory.html#grouping-groups-parent-child-group-relationships
https://bjpcjp.github.io/2022/07/07/ansible.html
An ad-hoc command in Ansible is a one-time command used to perform a task quickly, without writing a full playbook. These commands are very useful for tasks that you need to execute only once or infrequently, and they allow you to take immediate action without the overhead of playbook creation.
Key characteristics of ad-hoc commands include:
-
Simplicity: They are simple and straightforward to use, often consisting of just a single line in the terminal.
-
Quick Execution: Ideal for tasks that need to be executed quickly and don’t require the complex coordination and orchestration that playbooks provide.
-
Modules: Ad-hoc commands use Ansible modules, similar to tasks in a playbook. You specify the module and its arguments directly in the command line.
-
Inventory: Like playbooks, ad-hoc commands operate on the hosts specified in Ansible’s inventory file. You can target specific groups or individual hosts.
-
No Reusability: Unlike playbooks, ad-hoc commands are not saved for later reuse (unless you manually record them).
-
Limitations: They are not meant for complex operations. While you can execute any module, you cannot use the more advanced features of Ansible like roles, templates, or handlers.
An example of an ad-hoc command in Ansible could be checking the uptime of all servers in a group:
ansible webservers -m command -a "uptime"In this example:
ansibleis the Ansible command-line tool.webserversis the group of hosts in the Ansible inventory on which the command will be executed.-m commandspecifies the use of thecommandmodule.-a "uptime"provides the argument to the module, which is the commanduptimein this case.
This command will connect to all hosts in the webservers group and execute the uptime command, returning the results to your console.
Ansible roles
https://medium.com/edureka/ansible-roles-78d48578aca1
https://bjpcjp.github.io/pdfs/devops/ansible-playbooks-org.pdf