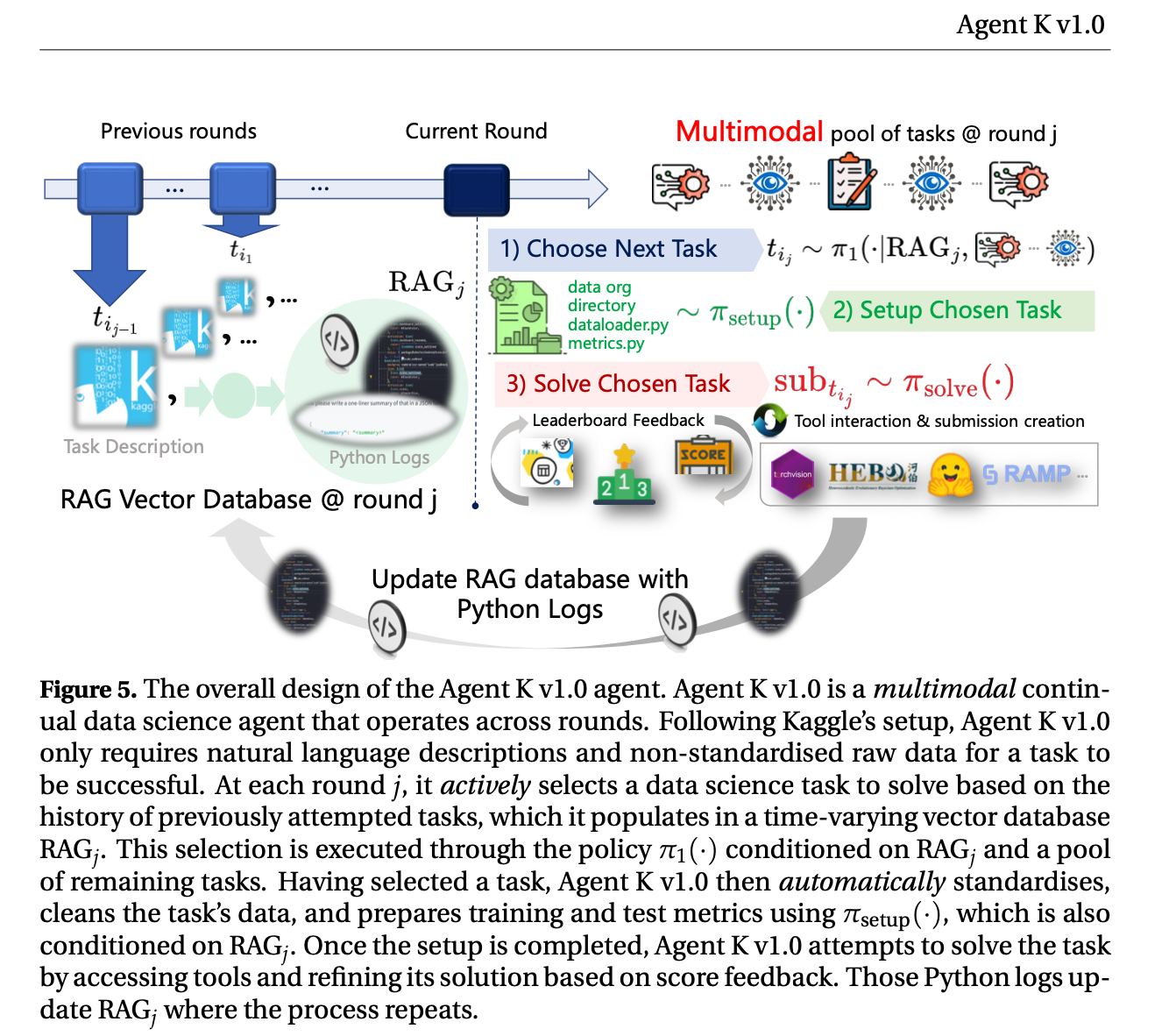
- flexible structured reasoning framework
- Agent K v1.0 optimises long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards.This iterative approach allows it to refine decisions without traditional fine-tuning or backpropagation, achieving continuous improvement through experiential learning
- common technique employed by traditional LLM agents often employs chain-of-thought (CoT) techniques [79, 81], generating answers or actions through a sequence of intermediate reasoning steps (as illustrated on the left in Figure 2). More advanced methods, like tree or graph of thought [5, 80, 88], enhance this process by exploring multiple reasoning paths at each step, which increases reliability. However, most prompting techniques, such as CoT or others, are inherently rigid and cannot learn directly from feedback, preventing them from adapting to optimise their reasoning. Typically, over- coming this limitation requires back-propagation [62], fine-tuning of the LLMs [54], or us- ing a reward model to guide the search process [20]. Still, those lack real-time flexibility and learning capabilities from feedback signals during task execution.
- learning-to-reason paradigm We hypothesise that LLMs possess inherent case-based reasoning capabilities [23], allowing them to generalise to new tasks using positive or negative past experiences. By optimising these experiences, learning and adaptation can occur naturally. We formu- late this by introducing structured reasoning, which integrates a memory module to dy- namically leverage past successes and failures for more adaptive learning (as indicated on the right side of Figure 2).
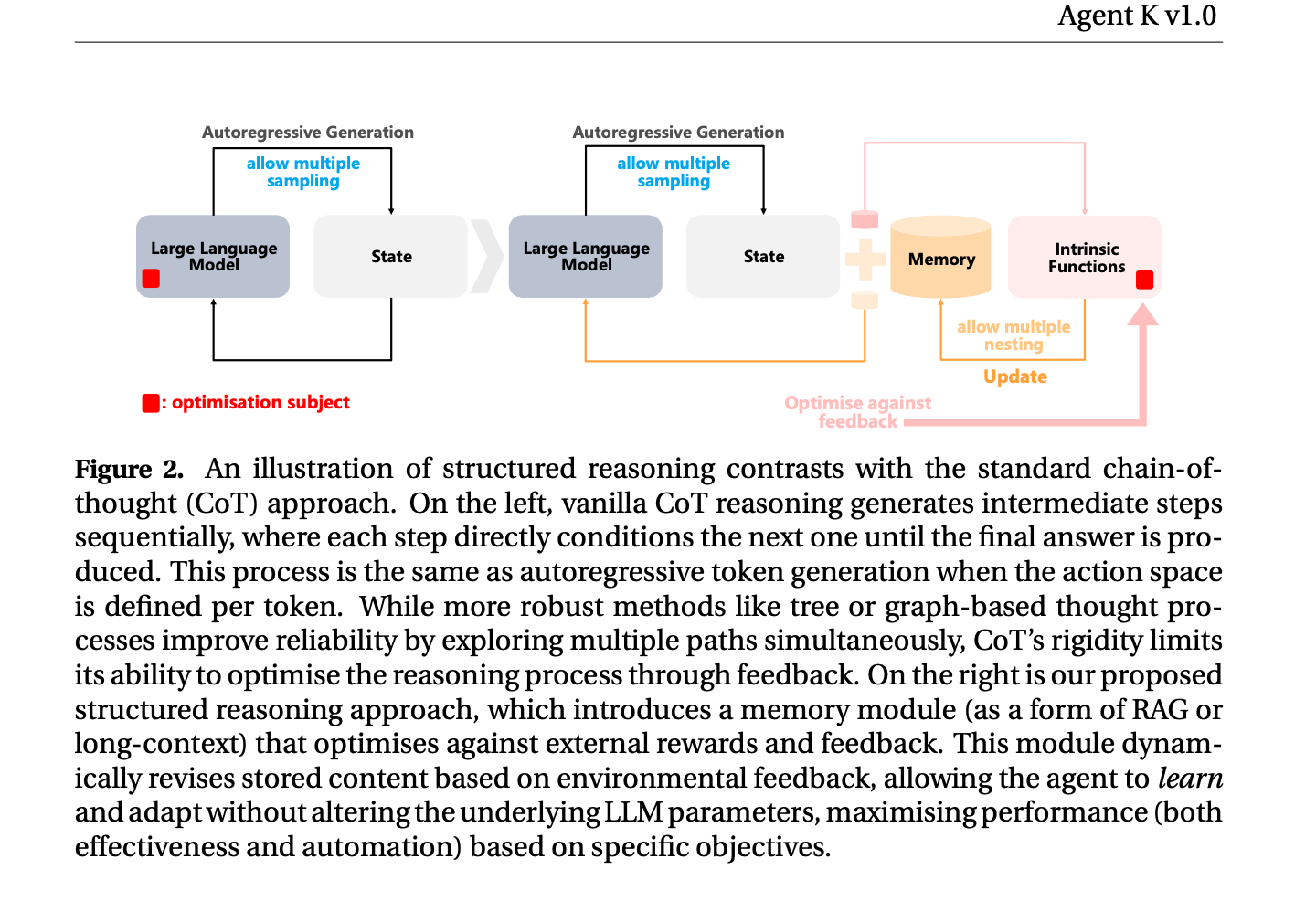
- This memory module allows the agent to store past experiences and adjust its strategies dynamically without retraining.
Learning to Reason by Experience
- Standard protocols for training LLMs rely on fine-tuning [54] and backpropagation [62], which are computationally heavy, memory-intensive and require extensive datasets to achieve meaningful improvements.
Markov Decision Processes and Agent K v1.0
The sources describe a novel approach for using Large Language Models (LLMs) to perform complex data science tasks. The authors frame the problem of data analysis, processing, and prediction as a Markov Decision Process (MDP), which allows them to leverage techniques from reinforcement learning to create a highly capable data science agent, Agent K v1.0.
Here’s how MDPs are utilized in Agent K:
-
Formalization: The data science process is modeled as an MDP, represented as M = ⟨Senv, A, P, R, γ⟩.
- Senv: This is the state space of the environment, representing all possible situations the agent might encounter during the data science task.
- A: The action space encompasses all possible actions the agent can take within the environment. This includes actions like generating code, cleaning data, selecting models, and submitting results.
- P: The transition probability function, P : Senv × A × Senv →, defines the probability of moving from one state to another given a specific action taken by the agent. For example, the probability of successfully cleaning a dataset given a specific code generation action.
- R: The reward function, R : Senv × A → ℝ, assigns a reward value to each state-action pair. This reward signal guides the agent’s learning process, encouraging actions that lead to desirable outcomes. For example, high accuracy on a validation set might yield a high reward.
- γ: The discount factor, γ ∈ [0, 1), balances the importance of immediate rewards against future rewards. A higher discount factor prioritizes long-term gains.
-
Learning Objective: The agent’s objective is to maximize the cumulative rewards it receives over time. It achieves this by learning an optimal policy that guides its decision-making.
-
Agent K’s Structure: Agent K uses three types of actions:
- Long-term Memory Actions (a(D)h): These actions manage the agent’s external database (Dh), which serves as long-term memory. This involves adding successful code snippets, data insights, and reasoning structures to the database or removing less effective ones based on their performance.
- Internal/Intrinsic Actions (a(M)h): These actions update the agent’s working memory (Mh) to shape its reasoning process. They include generating intermediate thoughts, retrieving relevant information from the external database, or interacting with tools.
- Extrinsic Actions (a(ext)h): These actions directly interact with the environment. This can involve modifying code, executing scripts, or submitting results to an external platform like Kaggle.
-
Structured Reasoning and Learning: Agent K employs structured reasoning, which allows it to dynamically adjust its internal memory and reasoning structure without retraining the underlying LLM. This is achieved through intrinsic functions that enable the agent to adapt its reasoning based on feedback from the environment and its own internal evaluations.
-
Credit Assignment: A crucial aspect of Agent K’s learning process is credit assignment, which involves determining which parts of its generated code or actions contributed to success or failure. The agent achieves this by analyzing error messages, reflecting on previous steps, and revisiting earlier stages of the process to refine its actions. This iterative process enables the agent to learn from its mistakes and improve its performance over time.
-
Multi-task Learning and Active Selection: To tackle diverse data science problems, Agent K is designed as a multi-task learner with active selection capabilities. It actively chooses which task to solve based on its past experiences, stored in retrieval databases (RAGj). The agent prioritizes tasks that are similar to previous successes and avoids tasks similar to previous failures. This selection process allows Agent K to build a curriculum of increasingly complex problems, enhancing its learning efficiency and knowledge transfer across domains.
-
Kaggle Grandmaster Level Performance: The effectiveness of Agent K is demonstrated by its ability to autonomously achieve a performance level comparable to human Kaggle Grandmasters, earning multiple gold, silver, and bronze medals across various competitions.
Agent K’s innovative use of MDPs and structured reasoning pushes the boundaries of data science automation. The agent’s ability to learn from experience, adapt to diverse tasks, and achieve high performance highlights the potential of LLMs as powerful tools for tackling complex real-world problems.