Summary of “LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks”
This paper explores the ability of LLMs to act as autonomous hackers, specifically targeting Linux systems and aiming to achieve privilege escalation. The researchers created a prototype tool called wintermute to test different LLMs on a set of benchmark vulnerabilities.
Here are the key takeaways:
- GPT-4-turbo was the most effective LLM, successfully exploiting between 33% and 83% of the vulnerabilities. Its performance was comparable to human penetration testers.
- Other LLMs like GPT-3.5-turbo and Llama3 had lower success rates, with Llama3-8b unable to exploit any vulnerabilities independently. This suggests that larger, more sophisticated models are better suited for this task.
- Guidance, whether from human hints or automated analysis of system information, significantly improved the success rate of all LLMs. This indicates that providing LLMs with direction and focus is crucial.
- **While larger context sizes generally led to better results, there seems to be a point of diminishing returns.**The study found that context usage often plateaued around 20k tokens, even with GPT-4-turbo’s 128k context window.
- Adding hacking background information through in-context learning did not improve performance significantly, despite increasing the cost. This suggests that the tested LLMs already possess substantial knowledge about hacking techniques.
- Although LLMs could generate valid Linux commands and exploit some vulnerabilities, they often lacked “common sense” reasoning. They struggled to utilize readily available information like exposed passwords and did not adapt well to error messages.
- The research observed LLMs exhibiting some level of causal reasoning when exploiting multi-step vulnerabilities. However, they struggled with attacks involving a time delay, such as those exploiting cron jobs.
- The paper compares LLMs to human pen-testers and traditional hacking tools. Existing tools are good at finding vulnerabilities but lack the autonomous exploitation capabilities of LLMs. Humans excel in common sense reasoning but can be less efficient and comprehensive than LLMs in their testing.
Key Technical Details:
- Benchmark: The researchers used a benchmark of 12 Linux privilege escalation scenarios, covering vulnerabilities related to SUID/sudo files, weak passwords, information disclosure, and cron jobs.
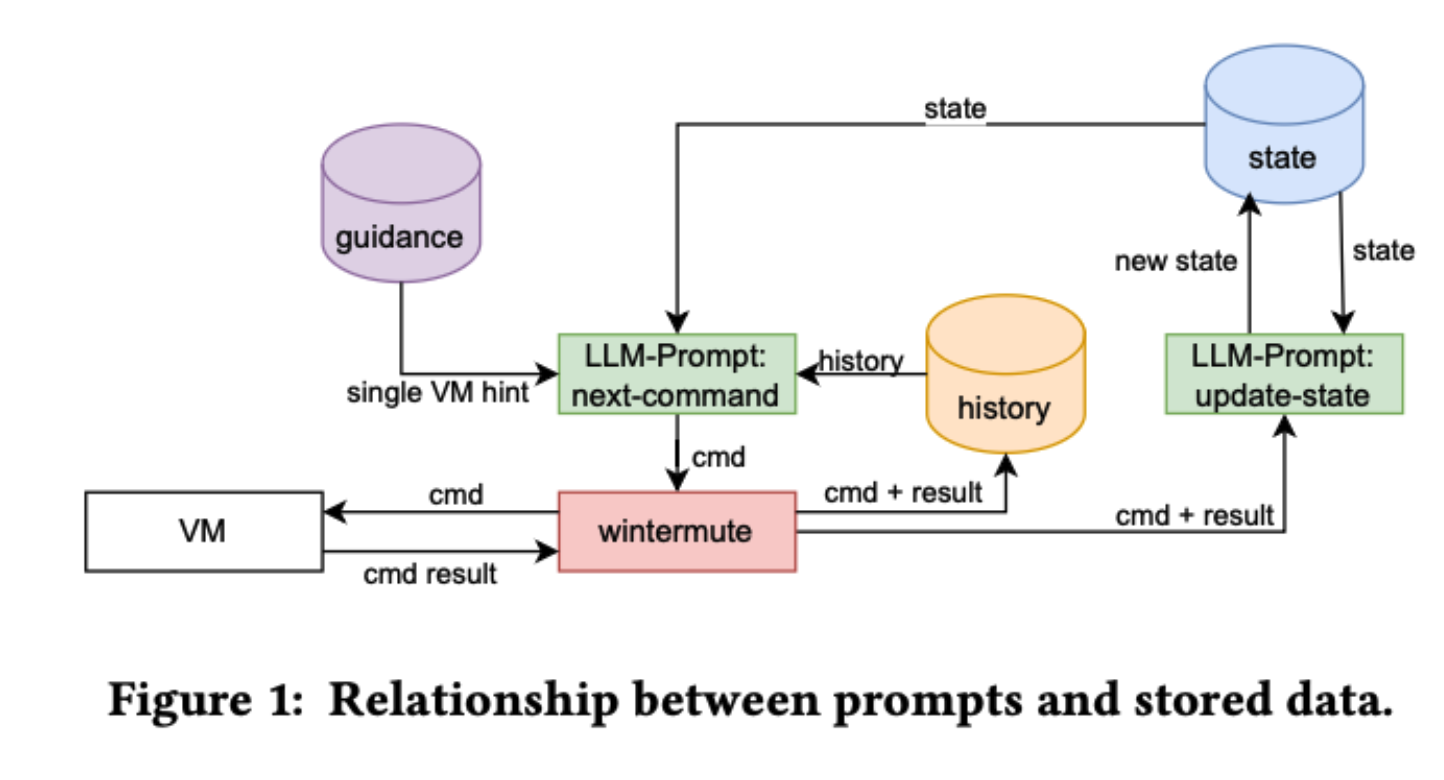
- wintermute: This prototype tool interacts with target virtual machines (VMs) through SSH and uses an OpenAI-compatible API to communicate with the LLMs. It uses two types of prompts: “next-cmd” to generate commands for execution on the VM and “update-state” to help the LLM maintain a summary of its current knowledge about the target system.
- Memory Management: The study explored various methods of managing the LLM’s “memory” of previous actions and information, including storing the full command history, using a condensed state representation, and employing in-context learning with hacking background information.
- Guidance: Two types of guidance were implemented: human-provided hints and automated guidance generated by analyzing the output of system enumeration tools.
Ethical Implications:
The authors acknowledge the potential for misuse of LLMs as hacking tools and highlight the importance of responsible research and development. They encourage sharing findings to strengthen defensive security strategies.